Acerca de los datos y otras decepciones
Navegando por el portal de los datos abiertos de la PGR, encontré una joya: Conjunto de datos de incidencia de delitos de robo de hidrocarburos a nivel nacional (https://datos.gob.mx/busca/dataset/robo-de-hidrocarburos). Pero encontré que los datos no solamente no están ordenados, sino mucho peor: están organizados en un formato terrible y hasta violento a la vista. Pocas veces he visto informes tan feos y poco amigables para el análisis (y vaya que he visto informes feos).
Y ni qué decir del tipo de archivo: un archivo con extensión RAR. ¿De verdad? ¿Será que quieren mantener los datos lejos de quien trate de analizarlos? No lo sabemos. Lo que sí puedo asegurar, es que este es un excelente proyecto para el blog: llevar un montón de datos sucios e ilegibles, a un formato donde los podamos analizar. Las tecnologías a usar para este post: Shiny.
0. Extraer información del archivo.
El enlace ofrece para descarga el archivo RoboHidrocarburos.rar. Si no tienes un compresor que lea estos archivos, puedes usar uno en línea (hay varios, solo googléalo). Cuando lo “destapes”, verás que incluye varios CSV (archivos separados por comas).

1. La lectura y reorganización de los datos.
Para esta publicación (esta es la tercera y última del tema), además de los datos de averiguaciones previas, incluí los datos de presuntos indiciados y las carpetas de investigación iniciadas. Los datos pasaron por varios procesos. En este archivo ( robo de hidrocarburos (ii) ) puedes ver cómo avancé de los datos desordenados a una tabla de datos legible y lista para el análisis. ¿Cómo determinar si los datos están ordenados o desordenados? Aquí seguimos tres reglas (ref: http://vita.had.co.nz/papers/tidy-data.pdf):
i) Cada columna es una variable.
ii). Cada fila es una observación.
iii) Una tabla representa una unidad de observación.
Al final hice una conciliación con los totales (para esta sección, no hay muchos datos de 2018). Las columnas están sombreadas en el tab 0. Recuerda que este proceso solo fue elaborado de esta manera para fines explicativos. Otra opción es hacer algunos ajustes en Excel, y después procesar en R (mucho más rápido y preciso).
Para que tengas una mejor noción de los cambios que se realizaron a estos datos: los datos está apilados, lo que hicimos fue desagregarlos, primero deshaciendo la columna única en campos (año, mes, delegación, delito), y después avancé descomponiendo las columnas, convirtiéndolas en observaciones (más que en representarlas como campos). El archivo va paso a paso.
2. Análisis de la información.
Para continuar con el análisis, ahora usaremos shiny (librería en R + RStudio para visualizaciones en web). Debajo de estas líneas, puedes verla aplicación. El enlace para ver a pantalla completa está al final del post.
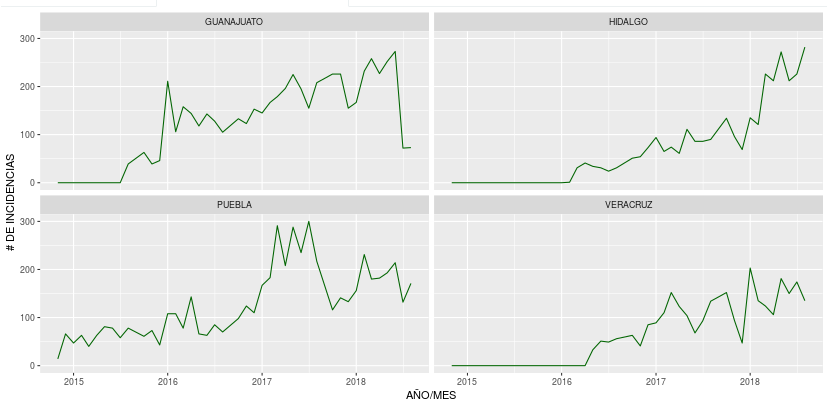
Esta es la última entrega. Se trata de la incorporación de las carpetas de investigación iniciadas. Y no hay nada que no se hay visto en las noticias: el centro del país es el más activo en carpetas de investigación iniciadas.
Desde luego, puedes distribuir los datos libremente, y te agradeceré una referencia a este sitio.
Ver aplicación en pantalla completa: https://fditf.shinyapps.io/roboDeHidrocarburos/